hive UDF笔记
1.编写代码
package com.billstudy.udf;import java.util.HashMap;import java.util.Map;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;/*** 自定义UDF函数* @author Bill* @since V1.0 2015年6月14日 - 下午10:33:00*/public class NationUDF extends UDF{public static Map<String,String> nationMap = new HashMap<String,String>();static {nationMap.put("china", "中国");nationMap.put("japan", "日本");nationMap.put("usa", "美国");}private Text returnNation = new Text();/*** 名称必须是evaluate* @author Bill* @since V1.0 2015年6月14日 - 下午10:32:41* @param nationKey* @return*/public Text evaluate(Text nationKey){String nation = nationMap.get(nationKey.toString());if (nation == null) {nation = "未知";}returnNation.set(nation);return returnNation;}}
2.加入jar
hive> add jar /home/hadoop/NationUDF.jar
3.创建函数
create tepmorary function nation as “com.billstudy.udf.NationUDF”
4.使用
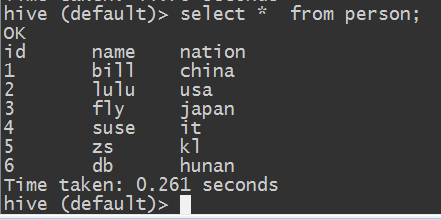
默认情况select * from person;
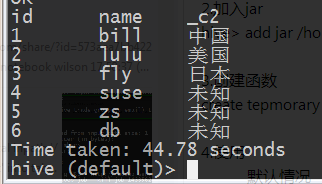
使用函数
select id,name,nation(nation) from person;
实验记录:
在第一次,自己没有往nationMap填充默认值时,也就是hive里面查询会显示所有的nation都是未知的,这个时候将代码修改后重新上传到上次add jar的位置(/home/hadoop/NationUDF.jar),hive可以自动使用新的jar。不需要重新add jar 然后再创建函数。