hbase 概念 + 搭建分布式HA应用
HBase – Hadoop Database
hbase的设计思想来自于google的bigtable
主键:Row Key
主键是用来检索记录的主键,访问Hbase table 中的行,只有三种方式
- 通过单个Row Key 访问
- 通过Row Key 的range
- 全表扫描
列族:Column Family
列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型
时间戳:Timestamp
Hbase中通过row和columns确定的为一个存储单元称为cell,每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引
角色功能:
Client
1.包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息
Zookeeper
1.保证任何时候,集群当中只有个master
2.存储所有Region的寻址入口
3.实时监控Regoin Server的状态,将Region Server的上线和下线信息实时通知给Master
4.存储Hbase的schema,包含有哪些table,每个table有哪些column family
Master
1.为Region server分配region
2.负责region server的负载均衡
3.发现失效的region server并重新分配其上的region(通过hdfs实现ha)
4.HDFS的垃圾回收
5.处理schema更新请求(ddl的操作)
Region Server
1.Region Server维护Master分配给它的region,处理对这些region的IO请求
2.Region Server负责切分在运行过程中变得过大的region
可以看到,client访问Hbase上的数据的过程并不需要master参与(寻址访问zookeeper和region server ),master仅仅维护着table和region的元数据信息,负载很低。但是不可缺
相比RDBMS特性:
- 没有真正的索引:行是顺序存储的,每行中的列也是,所以不存在索引膨胀的问题,而且插入的性能和表的大小无关
- 自动分区:在表增长的时候,表会自动分裂成region,并分布到可用的节点上
- 线性扩展和对于新节点的自动处理:增加一个节点,把它指向现有集群并运行regionserver. region自动重新进行平衡,负载均匀分布
- 普通商用硬件支持:集群可以用较低价格的机器来搭建节点(相对RDBMS),RDBMS需要支持大量IO,所以要求更昂贵的硬件.
- 容错:大量节点意味着每个节点的重要性并不突出,不用担心单个节点失效
- 批处理:MapReduce集成功能使我们可以用全并行分布式作业根据“数据的位置”(Location Awareness)来处理它们。
Memstore与storefile
- 一个region由多个store组成,每个store包含一个列族的所有数据
- Store包括位于把内存的memstore和位于硬盘的storefile
- 写操作先写入memstore,当memstore中的数据量达到某个阈值,HRegionServer会启动flashcache进程写入storefile,每次写入形成一个storefile
- 当storefile文件的数量增长到一定阈值后,系统会进行合并,在合并过程中会进行版本合并和删除工作,形成更大的storefile
- 当storefile大小超过一定阈值后,会把当前的region分割为两个,并由HMaster分配到相应的region服务器,实现负载均衡
- 客户端检索数据时,先在memstore找,找不到再找storefile.
Hbase里面有两张特殊的表:
.meta.:记录了用户创建的表Region信息,可以有多个region
-root-:记录了meta的位置
查询记录时,不指定版本默认查询最新版本。
搭建distributed clusted & HA 步骤:
目前集群情况:
7台机器:hadoop-server01 ~ hadoop-server07
NameNode:1,2有, 对外提供hdfs://ns1抽象路径,通过Zookeeper来控制Active以及standby节点
DFSZKFailoverController(zkfc):用作监控NameNode节点,定时向Zookeeper汇报健康情况,所以只有1,2有
DataNode:7台都有
NodeManager:7台都有
ResourceManager:3,4有
QuorumPeerMain:Zookpeeper进程,5,6,7有
JournalNode:共享NameNode的edits数据,也是5,6,7有
待会hbase要实现的目标:
1做HMaster(active),2和3做为HMaster(Backup),同时7台机器上都跑HRegionServer,实现HMaster(active)节点宕机后,自动通过Zookeeper实现切换
export JAVA_HOME=/usr/java/jdk1.7.0_55
//告诉hbase使用外部的zk
export HBASE_MANAGES_ZK=false
vim hbase-site.xml
<configuration>
<!– 指定hbase在HDFS上存储的路径 –>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!– 指定hbase是分布式的 –>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!– 指定zk的地址,多个用“,”分割 –>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-server05:2181,hadoop-server06:2181,hadoop-server07:2181</value>
</property>
</configuration>
vim regionservers
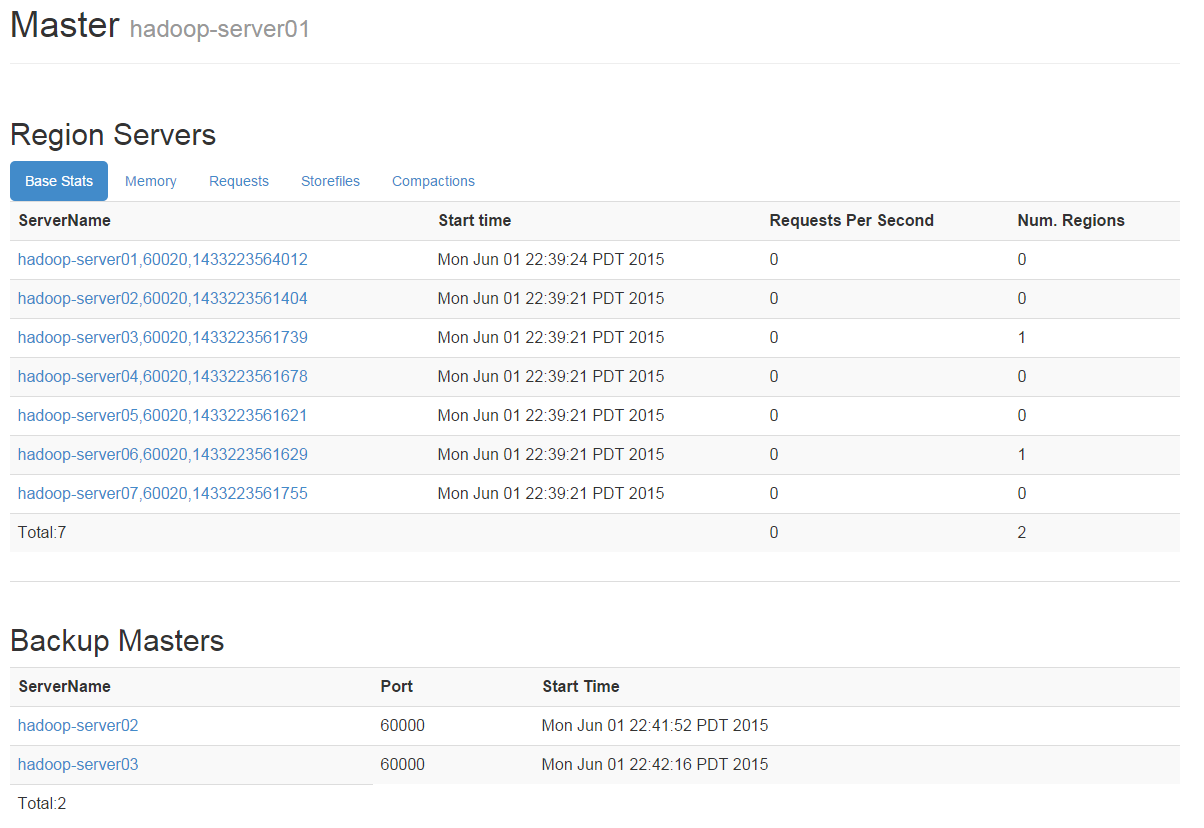
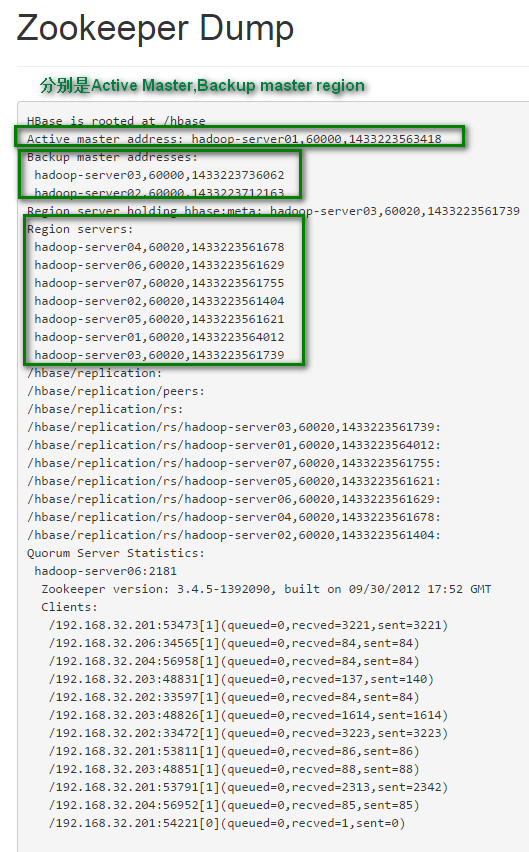
hadoop-server01hadoop-server02hadoop-server03hadoop-server04hadoop-server05hadoop-server06hadoop-server07cd ~/appscp_hadoop_many hbase/ $PWD如果没有批量自动化脚本,也可以分别使用scp拷贝。分别在5,6,7机器上启动ZookeeperzkServer.sh start启动hdfs集群start-dfs.sh启动Hbase集群 (在1机器上启动)start-hbase.sh为了HA,我在2,3也启动了hbase Masterhbase-daemon.sh start master现在就可以访问机器的60010查看hbase状态了。可以看到7个节点,并且有2个backup master访问:60010/zk.jsp 可以查看Zookeeper Dump附注:1.脚本 scp_hadoop_many#!/bin/bash
if [ $# -ne 2 ]thenecho “usage:<sourceFile> <targetFile>”exit 1fiips=(hadoop-server02 hadoop-server03 hadoop-server04 hadoop-server05 hadoop-server06 hadoop-server07)for ip in ${ips[*]}doscp -r $1 hadoop@$ip:$2done