Hive 测试笔记
1.创建普通学生表
load data local inpath ‘/home/hadoop/test-table/s1.txt’ into table student;
2.导入普通表数据
2.1 【 通过hive命令】
load data local inpath ‘/home/hadoop/test-table/s1.txt’ into table student;
2.2 【通过hadoop命令直接上传】
hadoop fs -put /home/hadoop/test-table/s1.txt /user/hive/warehouse/
3.创建外部表
create external table ext_student (id int , name string) row format delimited fields terminated by ‘\t’ location ‘/ext_student’;
4.导入外部表数据
4.1 【 通过hive命令】
load data local inpath ‘/home/hadoop/test-table/s2.txt’ into table ext_student;
4.2 【通过hadoop命令直接上传】
hadoop fs -put s1.txt /ext_student;
5.创建分区表
create table part_student (id int,name string) partitioned by (address string) row format delimited fields terminated by ‘\t’;
6.导入分区表数据
6.1 【 通过hive命令】
load data local inpath ‘/home/hadoop/test-table/s1.txt’ into table part_student partition (address=’hunan’);
load data local inpath ‘/home/hadoop/test-table/s2.txt’ into table part_student partition (address=’shanghai’);
load data local inpath ‘/home/hadoop/test-table/s3.txt’ into table part_student partition (address=’beijin’);
6.2 【通过hadoop命令直接上传】
hadoop fs -put s4.txt /user/hive/warehouse/part_student/address=zhongshan
*** 如果表是分区表,通过hadoop命令上传后hive里面会查询不到数据,这个和普通表、外部表不一样。
需要手动添加分区,因为在元数据表中不存在新增加的zhongshan分区,否则不会去读取新分区。
alter table part_student add partition (address=’zhongshan’);
测试Hive Join查询:
1.建立 user , trande表
SET FOREIGN_KEY_CHECKS=0;
— —————————-
— Table structure for `hive_trade`
— —————————-
DROP TABLE IF EXISTS `hive_trade`;
CREATE TABLE `hive_trade` (
`id` int(128) NOT NULL AUTO_INCREMENT,
`email` varchar(128) DEFAULT NULL,
`amount` double(128,0) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
— —————————-
— Records of hive_trade
— —————————-
INSERT INTO `hive_trade` VALUES (‘1’, ‘5938902321@qq.com’, ’20’);
INSERT INTO `hive_trade` VALUES (‘2’, ‘234234@qq.com’, ’32’);
INSERT INTO `hive_trade` VALUES (‘3’, ‘234234@qq.com’, ‘100’);
INSERT INTO `hive_trade` VALUES (‘4’, ‘092903@163@.com’, ‘5’);
INSERT INTO `hive_trade` VALUES (‘5’, ‘092903@163@.com’, ‘100’);
INSERT INTO `hive_trade` VALUES (‘6’, ‘flank@126.com’, ‘324’);
INSERT INTO `hive_trade` VALUES (‘7’, ‘flank@126.com’, ‘13132’);
INSERT INTO `hive_trade` VALUES (‘8’, ‘34324@sina.com’, ‘234553’);
INSERT INTO `hive_trade` VALUES (‘9’, ‘34324@sina.com’, ’33’);
INSERT INTO `hive_trade` VALUES (’10’, ‘34324@sina.com’, ’13’);
INSERT INTO `hive_trade` VALUES (’11’, ‘5938902321@qq.com’, ’12’);
INSERT INTO `hive_trade` VALUES (’12’, ‘5938902321@qq.com’, ‘12313’);
INSERT INTO `hive_trade` VALUES (’13’, ‘flank@126.com’, ’20’);
— —————————-
— Table structure for `hive_user`
— —————————-
DROP TABLE IF EXISTS `hive_user`;
CREATE TABLE `hive_user` (
`id` int(128) NOT NULL AUTO_INCREMENT,
`email` varchar(128) DEFAULT NULL,
`name` varchar(128) DEFAULT NULL,
`address` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
— —————————-
— Records of hive_user
— —————————-
INSERT INTO `hive_user` VALUES (‘1’, ‘5938902321@qq.com’, ‘Bill’, ‘湖南耒阳’);
INSERT INTO `hive_user` VALUES (‘2’, ‘234234@qq.com’, ‘fly’, ‘湖南郴州’);
INSERT INTO `hive_user` VALUES (‘3’, ‘092903@163@.com’, ‘su’, ‘上海’);
INSERT INTO `hive_user` VALUES (‘4’, ‘34324@sina.com’, ‘vence’, ‘北京’);
INSERT INTO `hive_user` VALUES (‘5’, ‘flank@126.com’, ‘flk’, ‘香港’);
2.在mysql中测试查询
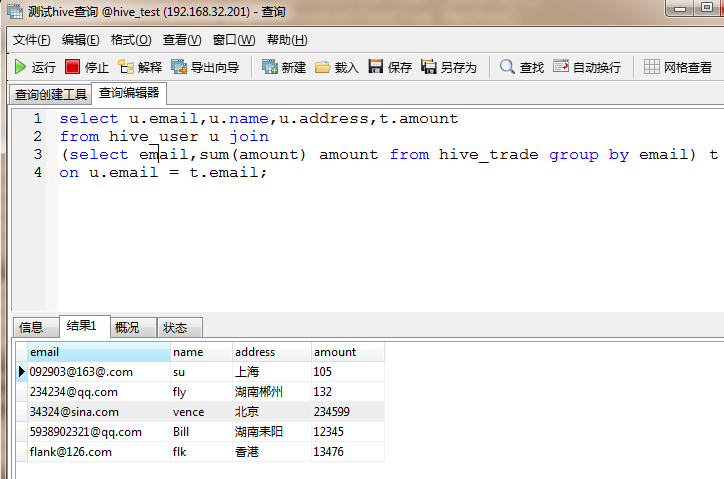
select u.email,u.name,u.address,t.amount
from hive_user u join
(select email,sum(amount) amount from hive_trade group by email) t
on u.email = t.email;
3.直接将mysql表导入到hive
3.1 hive_user表
sqoop import –connect jdbc:mysql://192.168.32.201:3306/hive_test –hive-import –hive-overwrite –hive-table hive_user –fields-terminated-by ‘\t’ –table hive_user –username root –password bill;
3.2 hive_trade
sqoop import –connect jdbc:mysql://192.168.32.201:3306/hive_test –hive-import –hive-overwrite –hive-table hive_trade –fields-terminated-by ‘\t’ –table hive_trade –username root –password bill;
4.在hive中执行上面mysql的查询语句
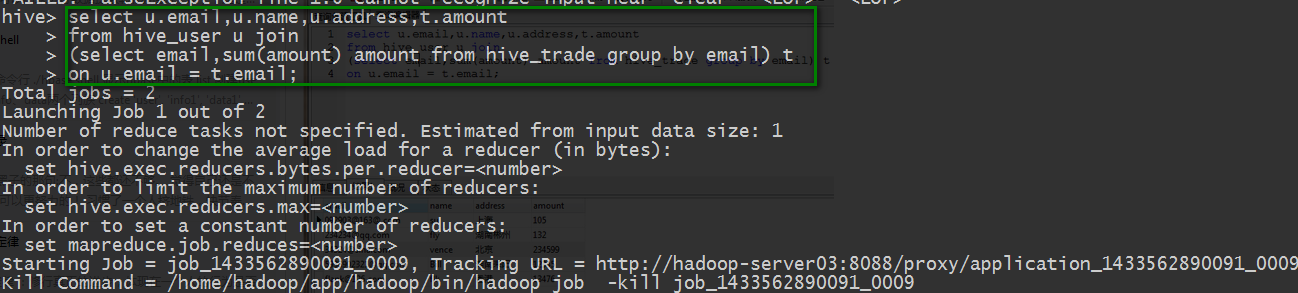
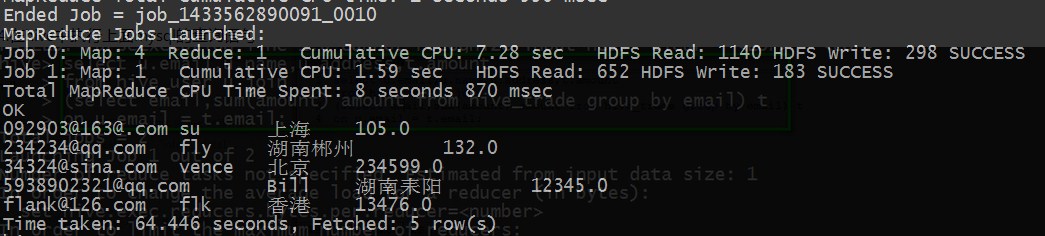
总结:在数据量小的情况下,hive相比mysql太慢了。但是数据量大的话,hive的速度比mysql快!
create table t6(id int,name String,salary float,person array<String>,love map<String,String>,address struct<street:String,city:String,zip:int>) row format delimited fields terminated by ‘\t’ collection items terminated by ‘\t’ map keys terminated by ‘\t’ lines terminated by ‘\n’ stored as textfile;